
La réplication MySQL est un levier fondamental dans l’architecture distribuée moderne, permettant de garantir la continuité des données et la haute disponibilité des bases de données. En synchronisant et en dupliquant efficacement les données entre serveurs, elle protège contre les pannes tout en optimisant la performance des lectures. Comprendre ses principes, ses modes de fonctionnement et ses limites est indispensable pour mettre en place un système solide et performant, capable de supporter les exigences croissantes des applications actuelles.
L’article en bref
La réplication MySQL offre une architecture robuste pour la gestion et la continuité des données. Ce guide technique détaille ses enjeux, modes, avantages et configurations clés.
- Archiver la performance : Répartition de la charge lecture pour fluidifier les accès.
- Assurer la disponibilité : Tolérance aux pannes grâce à des copies synchronisées.
- Comprendre les modes de réplication : Synchrone vs asynchrone et leurs impacts.
- Maîtriser la configuration : Implémentation Master-Slave pour une redondance efficace.
Une réplication bien pensée n’est pas un luxe mais une nécessité pour éviter tout risque de défaillance.
Les bases de la réplication MySQL pour une gestion optimale des données
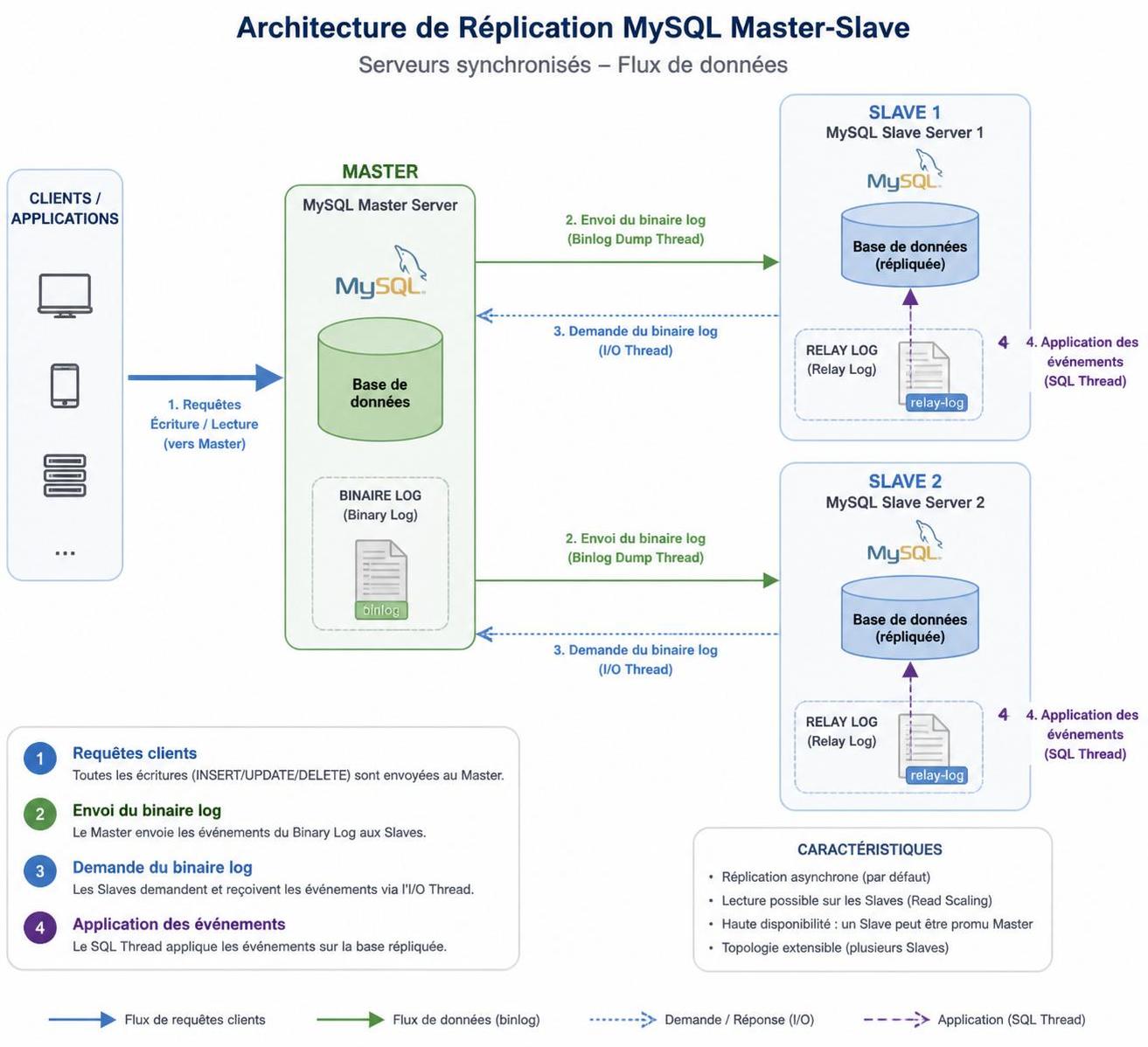
La réplication implique la création de copies identiques d’une base de données MySQL sur plusieurs serveurs. Ce mécanisme vise à maintenir une continuité des données, en permettant à des serveurs secondaires (répliques) de répondre aux requêtes de lecture et de prendre la relève en cas de panne du serveur principal. Le schéma Master-Slave, le plus courant, utilise un serveur maître pour gérer les écritures, tandis que plusieurs esclaves répliquent ces données et distribuent la charge des lectures.
Ce découpage optimisé améliore la performance globale en évitant la saturation du serveur maître tout en assurant une disponibilité accrue. Un point crucial reste toutefois la synchronisation des données : un décalage peut survenir entre maître et esclaves, impactant la cohérence et nécessitant une surveillance attentive.
Mode de réplication synchrone versus asynchrone : enjeux et choix techniques
Le choix entre réplication synchrone et asynchrone joue un rôle déterminant. En mode synchrone, l’écriture sur la base primaire est confirmée uniquement après que la mise à jour soit effective sur au moins une réplique secondaire. Cette garantie forte minimise la perte de données en cas de failover, mais au prix d’une latence accrue qui peut pénaliser la performance d’écriture.
À l’inverse, la réplication asynchrone offre une réactivité notable, car l’opération d’écriture est validée immédiatement, laissant un léger délai à la propagation des modifications. Ce mode est privilégié pour les applications axées sur la performance, acceptant une cohérence éventuelle, comme les réseaux sociaux ou plateformes Web à fort trafic.
| Critère | Réplication Synchrone | Réplication Asynchrone |
|---|---|---|
| Garantie de cohérence | Forte, aucune donnée perdue | Eventuelle, risque de délai |
| Latence d’écriture | Augmentée, attente confirmation | Minimale, validation immédiate |
| Cas d’utilisation | Transactions financières | Applications web à charge élevée |
| Impact sur performance | Peut être significatif | Optimisé |
Mise en place d’une architecture Master-Slave MySQL : étapes clés pour l’excellence opérationnelle
La mise en place de la réplication Master-Slave démarre par la configuration du serveur maître, avec l’activation du journal binaire (bin log). Celui-ci trace chaque modification, essentielle pour une synchronisation précise vers les répliques secondaires. Ces dernières sont configurées pour pointer vers le maître en spécifiant leurs identifiants, la position de départ dans le journal, et l’option cruciale log_slave_updates afin de conserver leurs propres journaux, utiles dans une chaîne multi-maîtres.
Avant de lancer la réplication, une sauvegarde exacte de la base maître est restaurée sur les esclaves pour garantir que tous démarrent sur une base identique. La surveillance de la réplication s’effectue via des commandes SQL dédiées telles que SHOW SLAVE STATUS, permettant de détecter rapidement les anomalies.
En cas d’accident sur le maître, le serveur esclave peut être promu manuellement pour assurer le failover et la continuité des opérations, renforçant ainsi la disponibilité du système. Cette orchestration demande rigueur et préparation pour limiter les interruptions.
Avantages et limites pratiques de la réplication MySQL Master-Slave
Les bénéfices sont tangibles :
- Haute disponibilité : un serveur esclave remplace rapidement le maître en cas de panne.
- Optimisation des performances : décharge des lectures sur les esclaves pour plus de fluidité.
- Sauvegarde continue : copies en temps réel pour une meilleure sécurité des données.
- Évolutivité horizontale : ajout facile de répliques pour absorber la charge.
Le revers : la réplication introduit une complexité opérationnelle certaine. Assurer la cohérence des données, gérer les conflits éventuels et veiller à un délai de réplication réduit requièrent une expertise continue. Un mauvais paramétrage peut aboutir à des pertes ou des décalages critiques pour l’application.
Surveillance et optimisation pour maintenir la fluidité de la réplication MySQL
Comme pour toute animation performante où chaque frame compte, la réplication exige une attention méticuleuse. Une latence excessive entre maître et esclaves peut dégrader l’expérience globale, notamment quand les lectures sur répliques renvoient des données obsolètes. La clé est d’utiliser les outils natifs MySQL et tout un écosystème de supervision pour détecter ces décalages dès leur apparition.
Les métriques importantes incluent la vitesse de lecture des logs binaires, le temps de traitement des événements sur les esclaves, et la charge réseau. Une optimisation passe aussi par le choix des bons paramètres système, la minimisation des écritures lourdes, et la limitation des opérations bloquantes sur la base maître. L’objectif est de maximiser la fluidité sans compromettre la stabilité.
Exemple en pratique : gérer les requêtes dans une application Hono avec réplication
Dans une application utilisant la réplication MySQL, la gestion intelligente des connexions évite les pièges habituels. Diriger toutes les requêtes d’écritures vers la base maître et répartir les lectures vers les esclaves permet de tirer parti de l’architecture distribuée tout en évitant les conflits et la surcharge.
Voici une illustration conceptuelle simplifiée :
app.post('/articles', async (c) => { // Écriture dirigée vers la base maître }); app.get('/articles/:id', async (c) => { // Lecture dirigée vers une réplique secondaire });
Cette séparation est capitale pour une performance maximale, avec un impact minimal sur le système. La gestion du failover reste prise en charge par le système de base de données ou des outils dédiés.
Pourquoi privilégier la réplication MySQL pour la continuité des données ?
Parce qu’elle assure une copie constante des informations sur plusieurs serveurs, permettant une tolérance aux pannes et une disponibilité sans faille.
Quelles sont les différences majeures entre réplication synchrone et asynchrone ?
La réplication synchrone garantit l’écriture sur toutes les répliques avant validation, assurant une cohérence stricte, tandis que la réplication asynchrone valide immédiatement l’écriture, avec un délai en propagation.
Comment surveiller efficacement la réplication MySQL ?
Utiliser les commandes MySQL comme SHOW SLAVE STATUS, associer des outils de monitoring en temps réel pour déclencher des alertes en cas de décalage ou erreurs.
Quels sont les avantages à utiliser un modèle Master-Slave ?
Ce modèle améliore la performance en séparant écritures et lectures, augmente la disponibilité du service, et facilite la gestion des sauvegardes et le failover.
Quelles sont les précautions à prendre lors du failover ?
La promotion d’une réplique en maître doit être coordonnée manuellement pour éviter les conflits et assurer la continuité sans corruption des données.



