
Structurer une base de données via un modèle logique solide est la clé pour garantir la cohérence, la performance et la scalabilité dans les projets informatiques. Le modèle logique agit comme un schéma relationnel indépendant des technologies, définissant avec précision les entités, leurs attributs, et les relations qui les lient. Cette étape intercalaire, entre la modélisation conceptuelle et l’implémentation physique, permet d’éviter les pièges courants liés à une conception précipitée. La normalisation, la gestion rigoureuse des clés et des contraintes assurent l’intégrité des données tout en facilitant le futur maintien et l’évolution des systèmes. À l’heure où les applications temps réel et l’IA brouillent les frontières entre différents types de traitement de données, choisir un bon modèle logique devient un levier décisif pour optimiser l’architecture de données globale.
L’article en bref
Maîtriser le modèle logique de données est incontournable pour aligner efficacement base, besoins métier et performances techniques, garantissant ainsi l’optimisation durable de projets complexes.
- Fondations claires : Le modèle logique formalise entités, relations et attributs sans contrainte technique.
- Normalisation maîtrisée : Supprimer redondances et anomalies pour garantir intégrité et performance.
- Choix du modèle adapté : Relationnel, NoSQL, dimensionnel selon les cas d’usage.
- Étapes incontournables : Conception conceptuelle, logique puis physique en chaîne itérative.
Le modèle logique n’est pas seulement un outil de conception : il optimise la structure pour des données cohérentes, évolutives et performantes, fondement d’une architecture efficace.
Le rôle central du modèle logique de données dans l’architecture de projets informatiques
Dans le paysage de 2026, où les frontières entre charges transactionnelles et analytiques s’estompent, un modèle logique bien construit assure une « santé » optimale de la base. En amont de la définition physique, il sert d’abstraction clarifiant les entités métier, leurs attributs et leurs relations. Cette étape vise à obtenir la meilleure structuration possible avant d’insérer les contraintes techniques liées à un SGBD spécifique. Ce découpage méthodique assure une base à toute épreuve, fluide dans son évolution.
Le modèle logique diffère de la modélisation conceptuelle qui reste plus proche du domaine métier : il affine et formalise les éléments structurels essentiels. Ainsi, la normalisation s’applique ici pour assurer la suppression des redondances et pour encadrer la validité des données via contraintes et règles d’intégrité bien définies. Ce travail s’inscrit dans une démarche agile et itérative garantissant la robustesse sur le long terme.
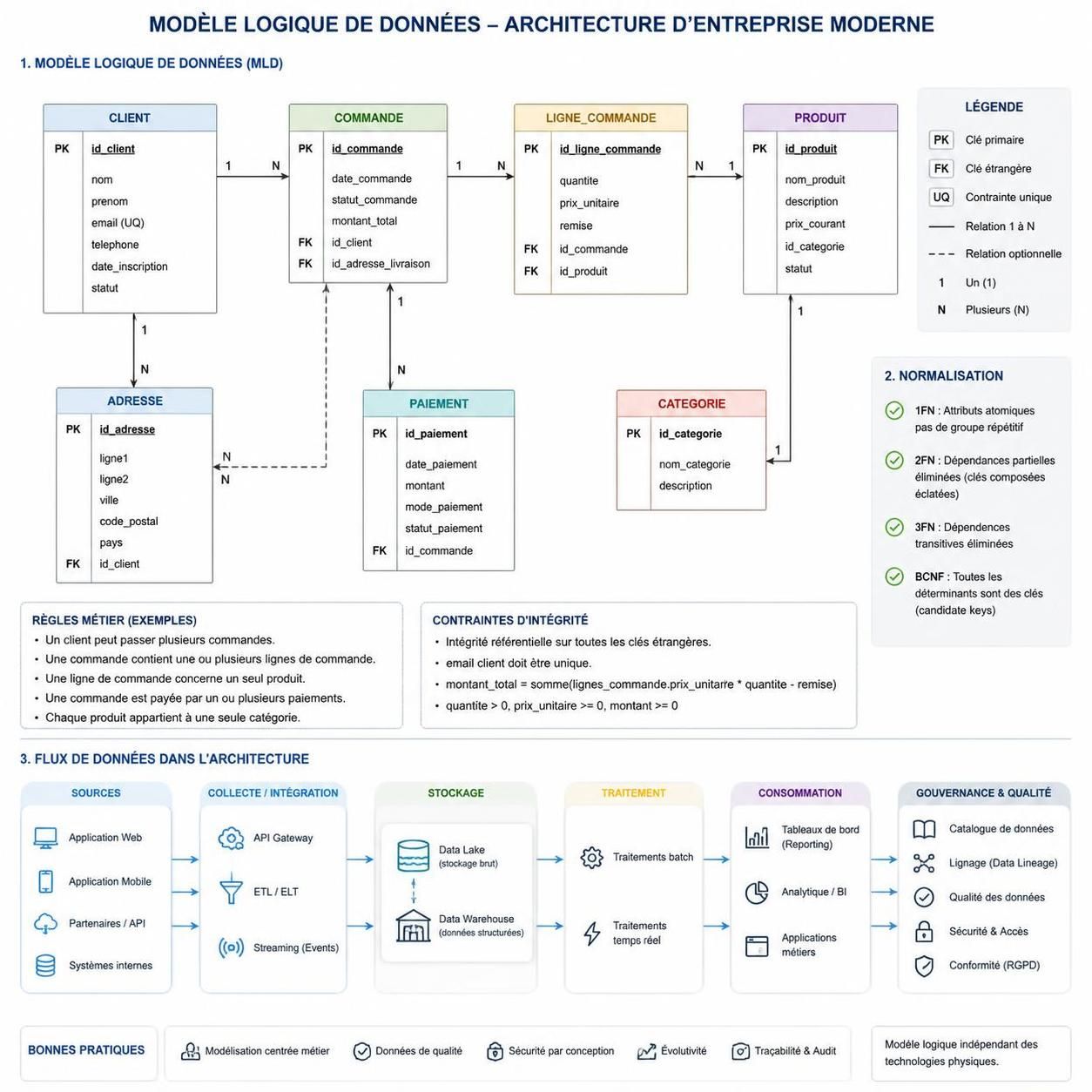
Clés de voûte : entités, attributs, relations et intégrité dans le modèle logique
Le modèle logique décompose chaque concept métier en entités précises munies d’attributs aux types définis. Une attention particulière est portée aux clés primaires, souvent substituts, assurant l’unicité de chaque enregistrement. Les <
La normalisation s’intègre en éliminant les attributs redondants et en isolant des dépendances pour prévenir anomalies et incohérences classiques (insertion, suppression, mise à jour). Cette démarche vise à privilégier une base de données performante et propre, le navigateur adore ça.
Processus de conception en trois temps pour structurer efficacement vos bases de données
On distingue généralement trois phases : conception conceptuelle (alignement métier, cartographie claire des entités principales), conception logique (précision technique sans contrainte SGBD), et conception physique (transposition en tables, index, paramètres spécifiques). Chaque étape apporte un niveau de détail et d’optimisation important.
Les choix du modèle sont cruciaux. Le modèle relationnel domine dans les environnements transactionnels exigeant cohérence forte. À l’inverse, les bases NoSQL, avec leurs schémas souples, conviennent pour un développement rapide et des données non structurées. Les modèles dimensionnels sont orientés analytique, optimisant business intelligence et reporting.
Bonnes pratiques : alignement et conventions pour un schéma lisible et adapté
Une documentation rigoureuse des conventions de nommage garantit la clarté, évitant les acronymes obscurs. Les clés doivent être choisies pour leur stabilité dans le temps, souvent des clés substitut à base d’UUID ou entiers auto-incrémentés. Toutes les contraintes liées aux clés étrangères, aux valeurs uniques ou au NOT NULL sont définies pour protéger le modèle contre les incohérences.
La validation via requêtes prototypes sur le modèle assure qu’il répond bien à la réalité métier, évitant ainsi des surprises à l’usage. Cette pratique s’inscrit dans la logique « moins de propriétés = plus de fluidité » qui optimise aussi l’usage des ressources en production.
Normalisation et dénormalisation : équilibre pour optimiser intégrité et performance
La normalisation garantit une intégrité optimale en évitant données dupliquées et erreurs fréquentes. Classiquement, les trois formes normales (1NF, 2NF, 3NF) organisent structuration et isolent redondances et dépendances. Par exemple, séparer clients et commandes évite les mises à jour risquées sur données répétées.
En contrepartie, certaines bases analytiques dénormalisent volontairement pour accélérer les lectures, réduire le nombre de jointures, simplifier les requêtes. Cette approche est d’autant plus efficace dans un contexte d’architecture de données lakehouse où le volume de données est très important et les traitements analytiques prédominent.
| Aspect | Normalisation | Dénormalisation |
|---|---|---|
| Objectif | Éliminer les redondances et anomalies | Optimiser la vitesse des lectures |
| Impact sur intégrité des données | Renforce via contraintes strictes | Peut réduire la cohérence stricte |
| Complexité des requêtes | Jointures complexes parfois nécessaires | Requêtes simplifiées, moins de jointures |
| Cas d’usage privilégié | Systèmes transactionnels, OLTP | Entreposage de données, BI, OLAP |
Les pièges à éviter pour un modèle logique propre et pérenne
- Sauter la conception conceptuelle : passer directement à la structure physique favorise la rigidité et l’inadaptation aux cas d’usage réels.
- Ignorer les clés étrangères : entraine données orphelines et incohérences d’intégrité.
- Conventions de nommage floues : impactent la maintenance et la collaboration.
- Sur-normalisation excessive : dégrade les performances transactionnelles par trop de jointures.
- Négliger l’indexation : à définir dès la conception physique pour éviter les goulots d’étranglement.
Modélisation moderne et outil collaboratif pour gagner en efficience
Les outils de création d’ERD, avec fonctionnalités de collaboration et versioning, permettent de bâtir progressivement de solides modèles de base. En intégrant cette pratique dans les cycles de développement, on assure un alignement constant avec les besoins métiers et techniques, garantissant la robustesse et la performance de la base. Le management des données via des solutions de pointe s’appuie sur ces modèles pour concevoir architectures unifiées où transactionnel et analyse cohabitent efficacement.
Le modèle logique ne doit donc pas être vu comme une simple démarche technique, mais bien comme le socle d’une architecture de données mature et optimisée qui profite pleinement des innovations actuelles, comme celles présentées dans les avancées en intelligence artificielle adaptée aux données. Il est temps de penser structuration rigoureuse pour des projets informatiques sans compromis.
Qu’est-ce qu’un modèle logique de données ?
C’est une étape de conception qui définit clairement les entités, attributs, relations et contraintes indépendamment de la technologie utilisée, préparant la construction de la base.
Pourquoi la normalisation est-elle importante ?
Elle supprime les redondances, évite les anomalies et garantit l’intégrité des données, contribuant à une base efficace et claire.
Quelles sont les phases clés de la modélisation ?
Conception conceptuelle, conception logique et conception physique qui se complètent pour produire un schéma cohérent et optimisé.
Quand utiliser un modèle NoSQL plutôt qu’un modèle relationnel ?
Lorsqu’on gère des données non structurées avec besoin de flexibilité et évolutivité rapide, NoSQL offre plus d’agilité.
Comment garantir la performance d’une base modélisée ?
En équilibrant normalisation et dénormalisation selon le contexte, en intégrant une indexation adaptée et en validant les requêtes types.



